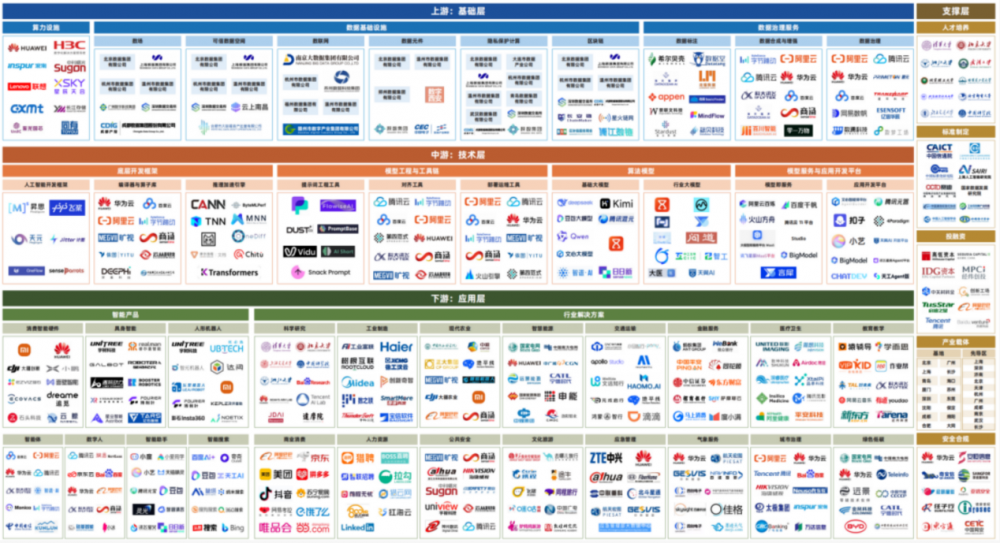
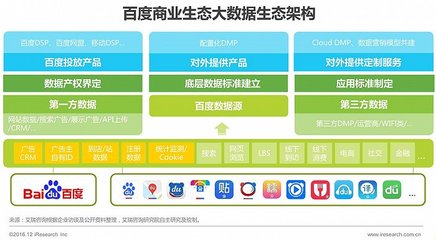
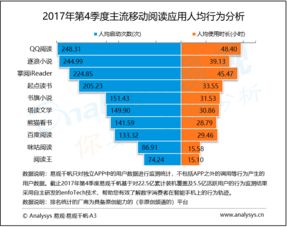
从草莽到高标准 互联网数据服务如何驱动NLP迈入4.0时代

在人工智能的浪潮中,自然语言处理(NLP)技术正以前所未有的速度重塑我们的世界。从智能客服到机器翻译,从情感分析到内容生成,NLP应用的每一次飞跃,其背后都离不开一个核心引擎:数据。而提供这些“燃料”的互联网数据服务行业,自身也经历了一场深刻的进化——从早期的“草莽时代”迈向了如今高精度、场景化的“4.0时代”。这一演变,正是NLP技术走向成熟和深化的缩影。
1.0 草莽时代:数据获取的原始积累
NLP的萌芽期,对数据的需求简单而粗放。互联网数据服务处于“草莽时代”,主要特点是海量、无标注、低质。服务商通过爬虫技术广泛抓取网页、论坛、新闻等公开文本,数据如同未经加工的矿石,体量巨大但杂质繁多。此时的NLP模型(如早期的统计模型)对数据质量要求不高,更多是进行词频统计、简单模式匹配。数据服务是“有总比没有好”的逻辑,缺乏统一的标准和深度处理。
2.0 工业化时代:标注流水线与基础质量
随着机器学习,尤其是监督学习的兴起,NLP进入了需要大量标注数据的阶段。数据服务随之步入“工业化时代”。这个阶段的核心是建立规模化的数据标注产线,对原始文本进行分词、词性标注、命名实体识别(如人名、地名)等基础标注。出现了众包平台和专业的标注团队,强调流程、效率与基础的一致性。质量往往停留在“正确”而非“优质”,标注规范相对宽泛,对复杂语言现象和上下文理解不足,难以满足更精细模型的需求。
3.0 精细化时代:任务导向与质量升级
当深度学习成为主流,特别是预训练模型(如BERT、GPT系列)出现后,NLP任务变得空前复杂和多样。数据服务进入“精细化时代”。其标志是 “任务导向”和“质量优先”。数据不再是一般性的标注,而是为特定下游任务量身定制,例如针对智能客服的精准意图识别和槽位填充数据,针对法律文书的专业关系抽取数据。质量评估维度极大丰富,不仅要求准确性,还关注数据多样性、偏差控制、场景覆盖度。数据服务商开始与算法团队深度协作,共同定义数据规范。
4.0 高标准时代:价值共创与生态化服务
如今,我们正站在NLP数据服务4.0的门槛上。这一时代的驱动力是大模型(Large Language Models)的爆发及其在千行百业的落地。4.0时代的特征是高标准的价值共创与生态化服务:
- 超高复杂度与认知智能:数据服务对象从传统NLP任务转向需要深层推理、知识关联、价值观对齐的大模型。所需数据可能是高度结构化的知识图谱、经过精细对齐的人类反馈数据(RLHF)、或融合多模态的复杂指令数据。
- 全链路与闭环服务:服务不再仅仅是提供数据集,而是覆盖 “数据战略咨询-定制化采集与生成-多轮精细标注与评测-数据持续迭代与治理” 的全生命周期。数据服务成为模型迭代闭环中的关键一环。
- 技术深度融合:积极利用AI来提升数据服务本身的质量和效率,例如用大模型进行数据清洗、自动标注、质量校验,甚至生成高质量的合成数据,实现“AI for Data”。
- 安全、合规与伦理成为基石:数据隐私保护、内容安全过滤、版权清晰、价值观对齐成为不可逾越的红线。高标准的数据合规体系是服务的核心基础设施。
- 行业Know-How深度绑定:在金融、医疗、法律等垂直领域,高质量数据必须与行业专业知识深度结合。数据服务商需要构建或整合领域知识库,提供具有行业洞察力的数据解决方案。
**
从草莽初辟到标准林立,NLP数据服务的进化史,也是一部NLP技术从实验室走向产业核心的奋斗史。4.0时代的数据服务,已从单纯的“原料供应商”转变为AI产业化的 “核心合作伙伴”和“质量守门人”** 。它意味着,未来NLP乃至整个人工智能的发展天花板,将在很大程度上取决于我们能否构建、治理和利用好更高标准、更富智慧的数据生态。这条从数据通往智能的道路,正变得前所未有的清晰,也要求着前所未有的专业与匠心。
如若转载,请注明出处:http://www.shijiannvwang.com/product/42.html
更新时间:2026-06-19 13:34:35